https://openai.com/research/gpt-4

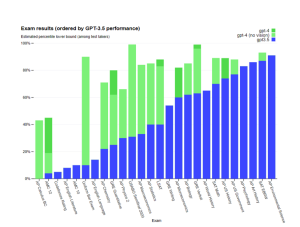
| Simulated exams | GPT-4estimated percentile | GPT-4 (no vision)estimated percentile | GPT-3.5estimated percentile |
| Uniform Bar Exam (MBE+MEE+MPT)1 | 298 / 400~90th | 298 / 400~90th | 213 / 400~10th |
| LSAT | 163~88th | 161~83rd | 149~40th |
| SAT Evidence-Based Reading & Writing | 710 / 800~93rd | 710 / 800~93rd | 670 / 800~87th |
| SAT Math | 700 / 800~89th | 690 / 800~89th | 590 / 800~70th |
| Graduate Record Examination (GRE) Quantitative | 163 / 170~80th | 157 / 170~62nd | 147 / 170~25th |
| Graduate Record Examination (GRE) Verbal | 169 / 170~99th | 165 / 170~96th | 154 / 170~63rd |
| Graduate Record Examination (GRE) Writing | 4 / 6~54th | 4 / 6~54th | 4 / 6~54th |
| USABO Semifinal Exam 2020 | 87 / 15099th–100th | 87 / 15099th–100th | 43 / 15031st–33rd |
| USNCO Local Section Exam 2022 | 36 / 60 | 38 / 60 | 24 / 60 |
| Medical Knowledge Self-Assessment Program | 75% | 75% | 53% |
| Codeforces Rating | 392below 5th | 392below 5th | 260below 5th |
| AP Art History | 586th–100th | 586th–100th | 586th–100th |
| AP Biology | 585th–100th | 585th–100th | 462nd–85th |
| AP Calculus BC | 443rd–59th | 443rd–59th | 10th–7th |
| AP Chemistry | 471st–88th | 471st–88th | 222nd–46th |
| AP English Language and Composition | 214th–44th | 214th–44th | 214th–44th |
| AP English Literature and Composition | 28th–22nd | 28th–22nd | 28th–22nd |
| AP Environmental Science | 591st–100th | 591st–100th | 591st–100th |
| AP Macroeconomics | 584th–100th | 584th–100th | 233rd–48th |
| AP Microeconomics | 582nd–100th | 460th–82nd | 460th–82nd |
| AP Physics 2 | 466th–84th | 466th–84th | 330th–66th |
| AP Psychology | 583rd–100th | 583rd–100th | 583rd–100th |
| AP Statistics | 585th–100th | 585th–100th | 340th–63rd |
| AP US Government | 588th–100th | 588th–100th | 477th–88th |
| AP US History | 589th–100th | 474th–89th | 474th–89th |
| AP World History | 465th–87th | 465th–87th | 465th–87th |
| AMC 10 | 30 / 1506th–12th | 36 / 15010th–19th | 36 / 15010th–19th |
| AMC 12 | 60 / 15045th–66th | 48 / 15019th–40th | 30 / 1504th–8th |
| Intro Sommelier (theory knowledge) | 92% | 92% | 80% |
| Certified Sommelier (theory knowledge) | 86% | 86% | 58% |
| Advanced Sommelier (theory knowledge) | 77% | 77% | 46% |
| Leetcode (easy) | 31 / 41 | 31 / 41 | 12 / 41 |
| Leetcode (medium) | 21 / 80 | 21 / 80 | 8 / 80 |
| Leetcode (hard) | 3 / 45 | 3 / 45 | 0 / 45 |
We also evaluated GPT-4 on traditional benchmarks designed for machine learning models. GPT-4 considerably outperforms existing large language models, alongside most state-of-the-art (SOTA) models which may include benchmark-specific crafting or additional training protocols:
| Benchmark |
GPT-4
Evaluated few-shot
|
GPT-3.5
Evaluated few-shot
|
LM SOTA
Best external LM evaluated few-shot
|
SOTA
Best external model (includes benchmark-specific training)
|
|
Multiple-choice questions in 57 subjects (professional & academic)
|
86.4%
5-shot
|
70.0%
5-shot
|
70.7%
|
75.2%
|
|
Commonsense reasoning around everyday events
|
95.3%
10-shot
|
85.5%
10-shot
|
84.2%
|
85.6%
|
|
Grade-school multiple choice science questions. Challenge-set.
|
96.3%
25-shot
|
85.2%
25-shot
|
84.2%
|
85.6%
|
|
Commonsense reasoning around pronoun resolution
|
87.5%
5-shot
|
81.6%
5-shot
|
84.2%
|
85.6%
|
|
Python coding tasks
|
67.0%
0-shot
|
48.1%
0-shot
|
26.2%
|
65.8%
|
|
DROP (f1 score)
Reading comprehension & arithmetic.
|
80.9
3-shot
|
64.1
3-shot
|
70.8
|
88.4
|
Many existing ML benchmarks are written in English. To get an initial sense of capability in other languages, we translated the MMLU benchmark—a suite of 14,000 multiple-choice problems spanning 57 subjects—into a variety of languages using Azure Translate (see Appendix). In the 24 of 26 languages tested, GPT-4 outperforms the English-language performance of GPT-3.5 and other LLMs (Chinchilla, PaLM), including for low-resource languages such as Latvian, Welsh, and Swahili:
We’ve also been using GPT-4 internally, with great impact on functions like support, sales, content moderation, and programming. We also are using it to assist humans in evaluating AI outputs, starting the second phase in our alignment strategy.
Visual inputs
GPT-4 can accept a prompt of text and images, which—parallel to the text-only setting—lets the user specify any vision or language task. Specifically, it generates text outputs (natural language, code, etc.) given inputs consisting of interspersed text and images. Over a range of domains—including documents with text and photographs, diagrams, or screenshots—GPT-4 exhibits similar capabilities as it does on text-only inputs. Furthermore, it can be augmented with test-time techniques that were developed for text-only language models, including few-shot and chain-of-thought prompting. Image inputs are still a research preview and not publicly available.

0 Responses
Stay in touch with the conversation, subscribe to the RSS feed for comments on this post.